In this article we will cover, in detail, how we can connect Amazon Redshift data source using Helical Insight and create reports/dashboard using it.
Prerequisites :
- Amazon Redshift Cluster instance on Amazon Web Services.
Following are the steps to create report with Helical Insight using Amazon Redshift:
- Dialect Configuration
- Datasource Creation
- Metadata Creation
- Adhoc Reports
Dialect Configuration
Dialect is used for generating SQL query as per the database selected. In Helical Insight Application, following are the steps to configure dialect :
- Go to
hi-repository/System/Admin. - Open “sqlDialects.properties” file in edit mode using text-editor such as notepad, notepad++.
- Add the below present line at the end of the file in a new line.
com.amazon.redshift.jdbc.Driver=org.hibernate.dialect.PostgreSQLDialect - Now, save the file.

Note : In case, dialect is not assigned then by default MySQL dialect is mapped with the selected database. In result, a sql query will be generated which may or may not support the selected database.
Create Datasource
This process involves establishing a connection between Helical Insight application and a Source Databases.
There are 2 methods available for creating a Datasource in Helical Insight:
- Front End Approach
- Back End Approach
Following are the steps shown below to create datasource using available methods :
Method 1 : Front End Approach
- Login to Helical Insight Application. ( For default credentials, click here )
- Click on “Home” button and select “Adhoc” from the list.
- On entering Adhoc Page, click on “Create” button in Datasources
- Select the “DataSource Type” from the given list. In this case, “Managed Datasource” will be used.
- Then, enter “DataSource Name” say “redshift cluster” ( any name can be assigned ) and select driver from the given list. Here, redshift jdbc driver will be selected with the name “com.amazon.redshift.jdbc.Driver”.
- Download the latest Amazon Redshift JDBC Driver. Click here to download.
- Once you have downloaded the driver, you need to put that driver in a specific folder and then immediately it will start appearing in the drop down list of Datasource. Click here for more details
- Enter the URL which is a JDBC URL. Like one shown below
- Enter Username which is a Master Username.
- Then, enter Password which is a Mater Password.
- Now, click on “Test Connection” in order to verify entered credentials.
- After clicking Test Connection, if the connection is established then a notification “The connection test is successful” appears.
- Click “Save DataSource”
- Hereon, a connection is established with an intended redshift cluster present on Amazon Server.
- Then, next step involves creation of metadata. After saving datasource, from the same page, click on “Metadata” (at the top right )
- Then, click on “Workflow”.

Note : In case, the redshift database driver is not present in the list then externally the list can be updated.
Following are the steps to update list :

Sample URL :
jdbc:redshift://hirdstest.cuqoxvtywysw.us-west-2.redshift.amazonaws.com:5439/hidbtest

Note: If there are multiple redshift cluster present on Amazon Server then separate datasource connection needs to be created in Helical Insight.
Further steps will be covered in “Metadata Workflow” step.
Method 2 : Back End Approach
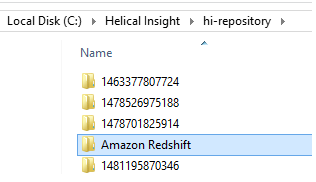
- Go to “hi-repository” folder where a Helical Insight Application is installed and then open the folder.
- Create a New Folder with any name say “Amazon Redshift” inside “hi-repository” folder.
- Now, open a text-editor like notepad, notepad++ , and so on.
- Then enter the following details as given below :
- Connection ID : User can assign any ID (numeric and unique)
- name : Name of the Datasource to be shown in the Datasource list
- Url : JDBC URL can be accessed from Cluster Configuration details. Like one shown below.

- User: Database Username
- Password: Database password
- After entering the details, save the file as “filename.efwd”
Note: Saved file has to be present inside the “Amazon Redshift” folder of “hi-repository“.
- Now, the Redshift connection has been established. ( if entered details are correct )
- Then, next step involves creation on metadata.
- Now, login to Helical Insight Application using any web browser.
- Click on “Home” button and select “Adhoc” from the list.
- Then, Click on “Metadata” Tab and then select “Workflow”.
C:\Helical Insight\hi-repository
<EFWD>
<DataSources>
<Connection id="1" name="Redshift Cluster EFWD" type="sql.jdbc">
<Driver>com.amazon.redshift.jdbc.driver</Driver>
<Url>jdbc:redshift://hirdstest.cuqoxvtywysw.us-west-2.redshift.amazonaws.com:5439/hidbtest</Url>
<User>hirdsuser</User>
<Pass>Hirdsuser1</Pass>
</Connection>
</DataSources>
</EFWD>
Further steps will be covered in “Metadata Workflow” step.
Create Metadata
For creating a metadata it is mandatory to have established datasource connection which is explained in create datasource.
- On clicking “Workflow” from “Metadata” tab, “Datasource Type” selection page is displayed.
- Select the “DataSource Type” from the given list.
- For Method 1 : Select DataSource Type: Managed Datasource
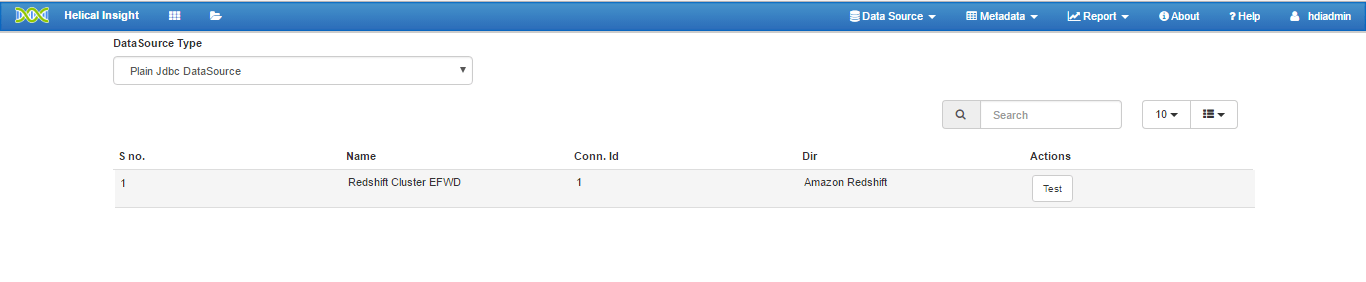
- For Method 2 : Select DataSource Type: Plain JDBC Datasource
- Click on the Datasource Name using which metadata will be created.
- For Method 1 : Datasource Name “redshift cluster” is used. Any name can be assigned during configuration of datasource.
- For Method 2 : Datasource Name “Redshift Cluster EFWD” is used. Any name can be assigned during configuration of datasource in efwd file.
- After clicking the datasource name, a window will show available catalogs and schemas. Now click one radio button to select intended catalog and schema (here schema selected is public)
- Now, select the required table from table list, and click Next
- After table selection, select required columns from selected tables, and click Next
- Now , a metadata page appears where various operations can be performed such as table/column aliasing, defining joins, creating views and apply table/column/data security conditions.
- Click on “Save” to create metadata.
- After clicking “Save” button, a window will appear known as File Browser. Using File Browser, a metadata file is saved in the file-repository of Helical Insight.
- Then, click on “Save Metadata” to confirm.
- Now, metadata file is ready for creating Adhoc Reports.






Adhoc Reports :
Now using created Redshift metadata you can create adhoc report, how to create Adhoc Report, click here
For further assistance, kindly contact us on support@helicalinsight.com or post your queries at forum.helicalinsight.com
