Starting from Helical Insight Enterprise Edition 5.2.2 onwards, we are providing an in-built driver to connect to and use flat files like Excel, CSV, JSON, and Parquet. Hence, without the need of using any middlewares (like Drill etc) now you can directly connect and use CSV within Helical Insight.
We are providing detailed information on how to connect to and use CSV files :
1. Log in to your Helical Insight application and go to the “Data Sources” module.
2. Once you are on “Data Sources” module, you will see many options to connect to different databases. Out of that you need to choose “Flatfile csv”. You can make use of search option at the top right also to search for this specific driver Reference image is provided below:
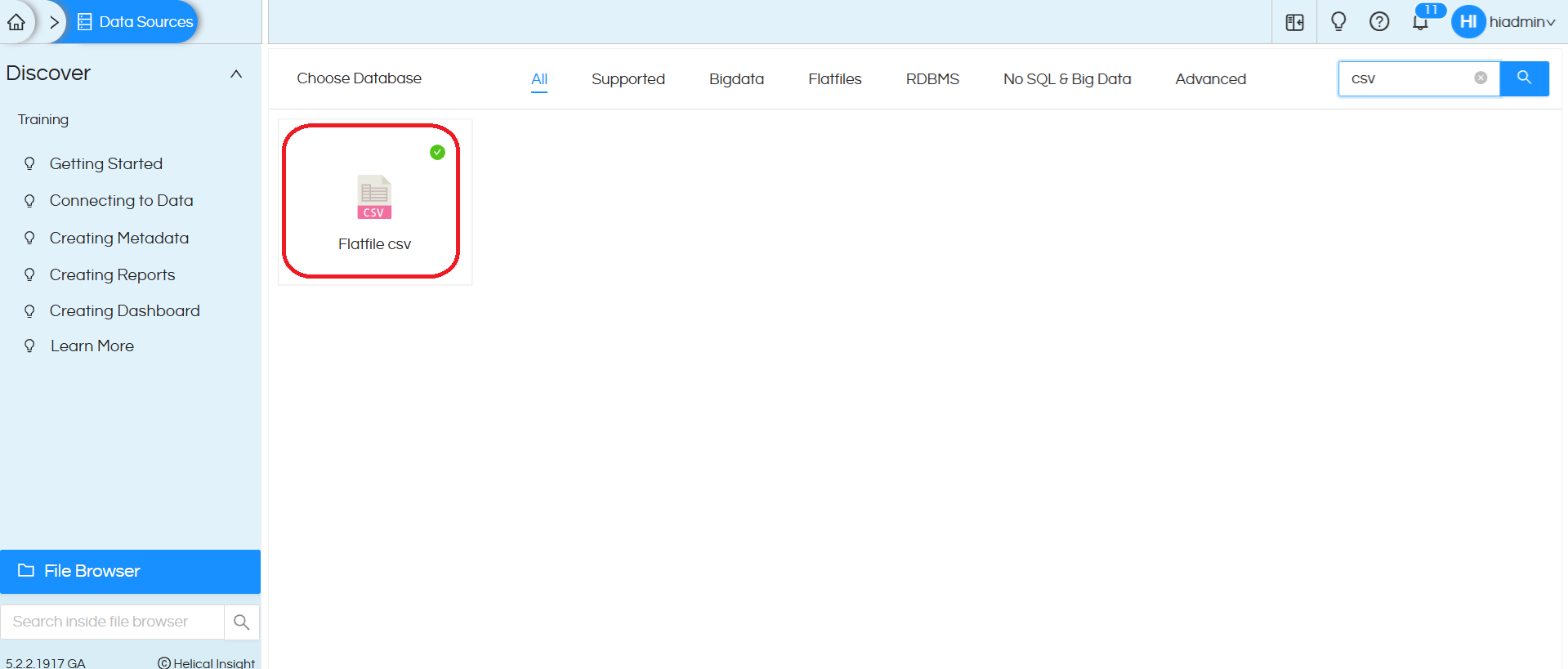
3. Once you click on ‘Flatfile csv‘ and choose ‘Create‘, a popup will open. Reference image is provided below
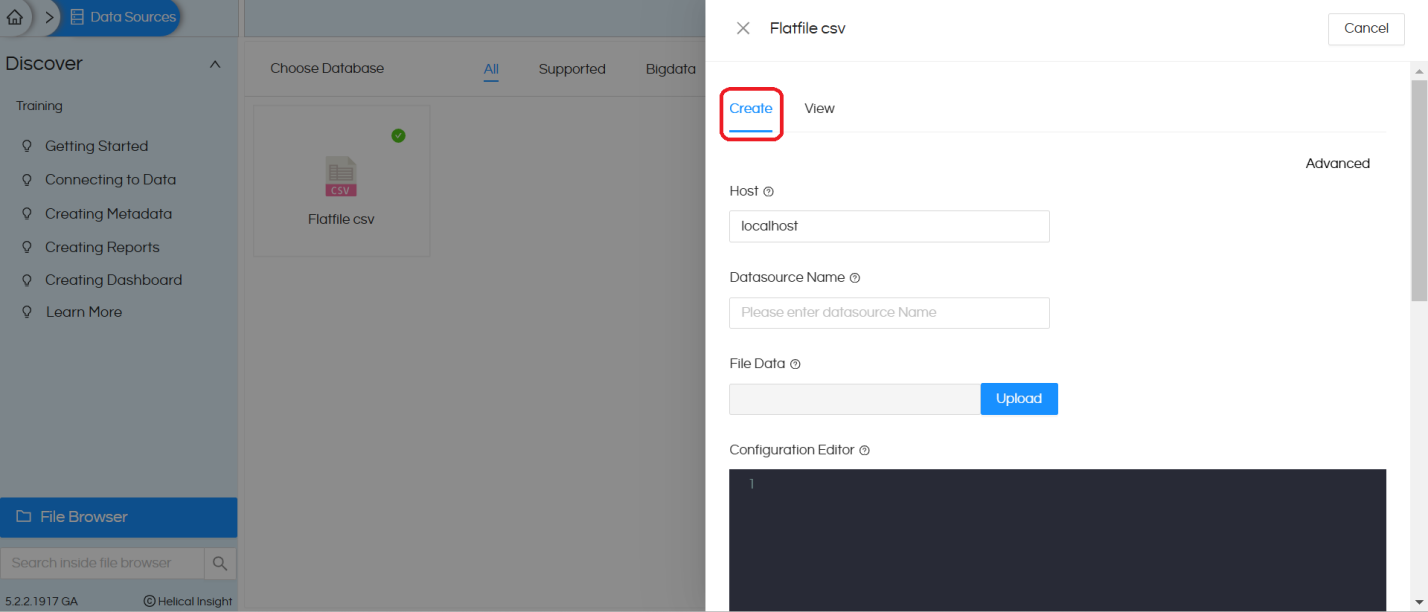
4. Host: It can be provided in two ways:
a. Upload the file: If we upload a csv file using the upload option, that file will get uploaded at a specific location in the Helical Insight server and this host section will be filled automatically.
b. Manually provide the csv file path: In this case, the file must be present on the same server where the Helical Insight server is installed and then in the host you will put something like below.
Example for linux path: /usr/local/traveldata.csv
We recommend using the file Upload option
5. In the “Datasource Name” section, we can provide any name of our choice with which the connection name will be saved and listed.
6. In the ‘Configuration Editor‘ we need to provide the configuration details. These details generally change based on the type of flat file being used. In most cases your connection to CSV will work as it is without even the need to go here and make any changes. In most cases you can give Connection Name, Test Connection, Save Connection. And then you can “Create Metadata” and further use Helical Insight.
ADVANCED USE CASES:
There are a lot of other configuration options which are also present. These configuration options can be used for more advanced use cases. In most cases it would not be required though to be tweaked. Some of them we have described below.
7. All the sample configuration details are provided on the icon next to the ‘Configuration Editor‘ An image is provided below
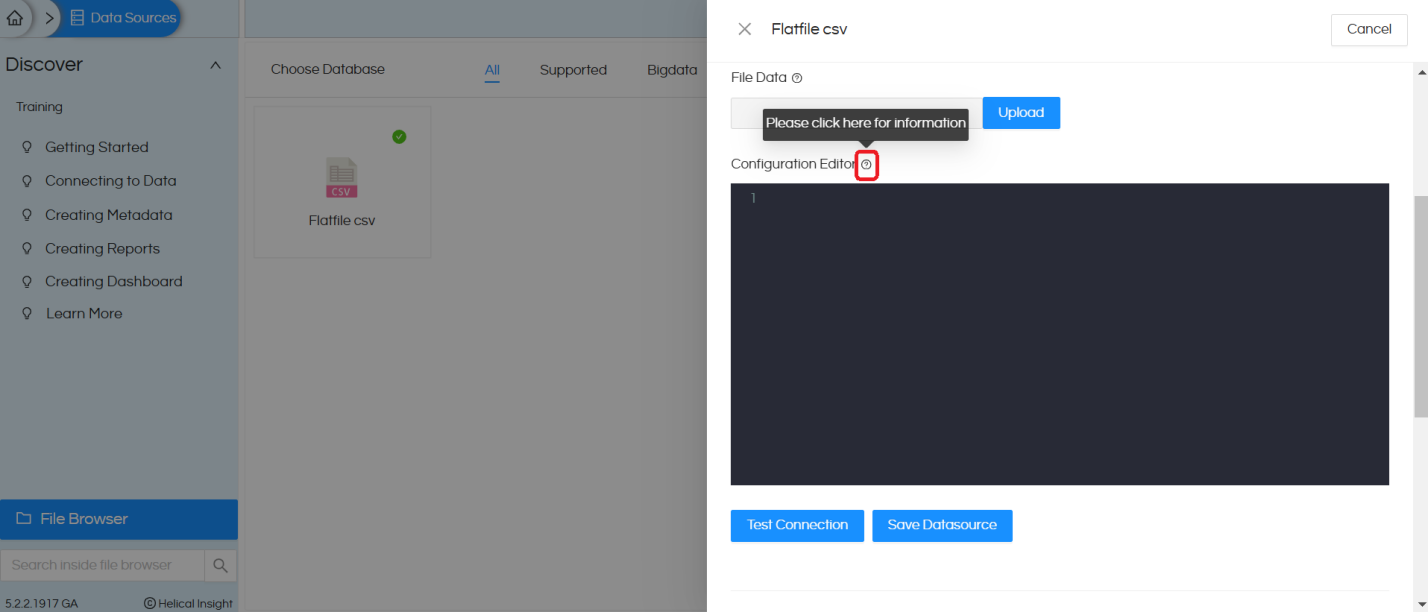
8. Once you click on this icon, it will open a pop up with all the configurations for different flat files.
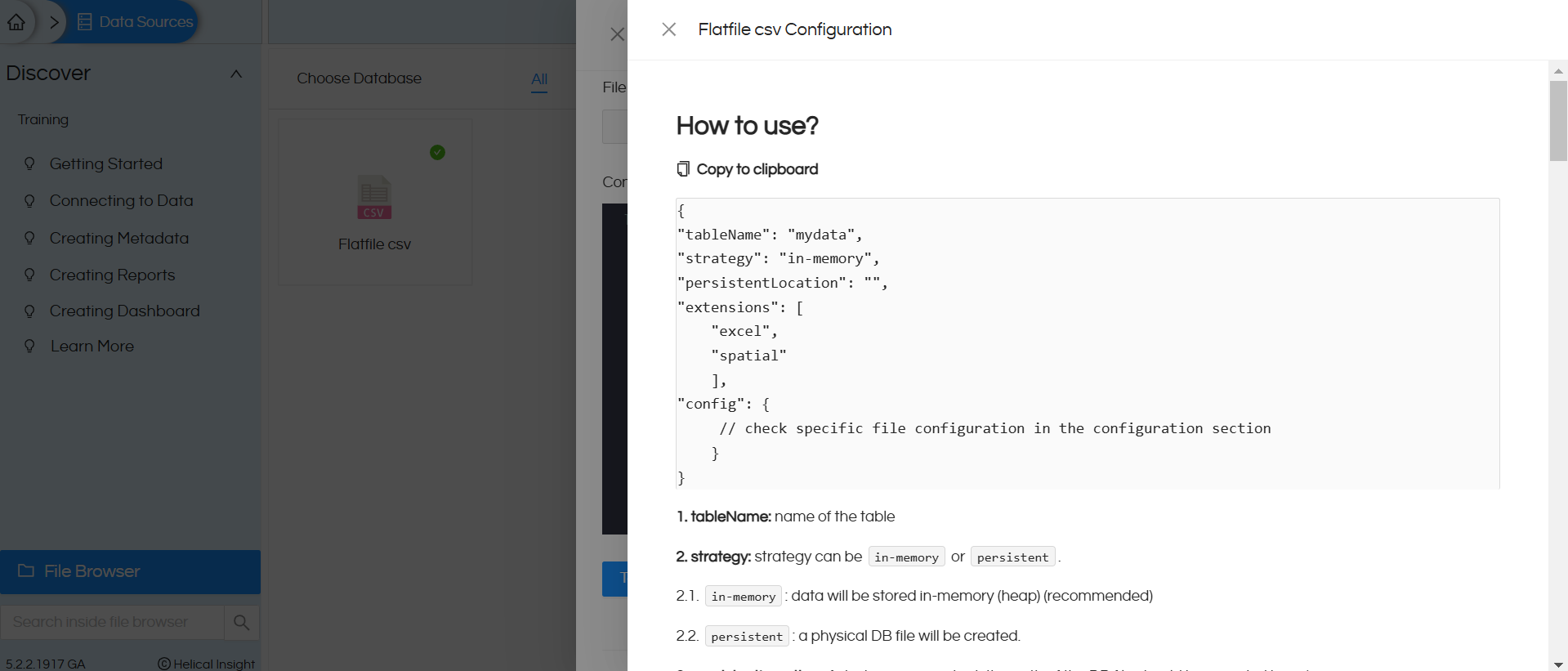
You will get direct “Copy to clipboard”, option which you can use to copy the content. You need to make necessary changes based on your details.
Explanation of configuration options :
1. tableName:
Value: "mydata" Explanation: This specifies the name of the table that will be created or referenced when you create the metadata. In this above case, the table will be created with the name mydata.
2. strategy:
Value: "in-memory" Explanation: Specifies the data processing strategy. "in-memory": Data will be processed and stored temporarily in memory, without persistence to a physical location ( Recommended approach). "persistent": Data will be persisted to a physical database file for storage. When the sizes of file are very huge, then this strategy is recommended.
3. persistentLocation:
Value: "" (empty string) Explanation: Indicates the location for persistent storage when the strategy is set to "persistent". For inmemory this setting can be ignored. If the strategy is "persistent", a valid file path must be specified here (e.g., C:\\dbs\\test.duckdb). When left empty, no persistent storage is configured.
4. extensions:
Value: ["excel", "spatial"] Explanation: Specifies the supported file types or processing extensions. For CSV, we should have either excel or spatial. "excel" enables the configuration to handle Excel files. "spatial" may indicate support for spatial
5. config:
This section contains additional configuration details for processing the flat file.
a. layer:
Value: ["sheet 1", "sheet 2"] Explanation: Specifies the sheet(s) in the Excel file to be processed. Excel file can have multiple sheets and you can specify which all sheets (their names) should be used like the above. If some sheet name is not provided that will get ignored. No need to put this for CSV.
b. open_options:
Value: ["HEADERS=FORCE", "FIELD_TYPES=AUTO"] Explanation: These are options for interpreting and processing the data. "HEADERS=FORCE" ensures that the first row of the sheet is treated as headers, even if this is not explicitly set in the CSV file. "FIELD_TYPES=AUTO" enables automatic detection and assignment of field types (e.g., string, integer, date).
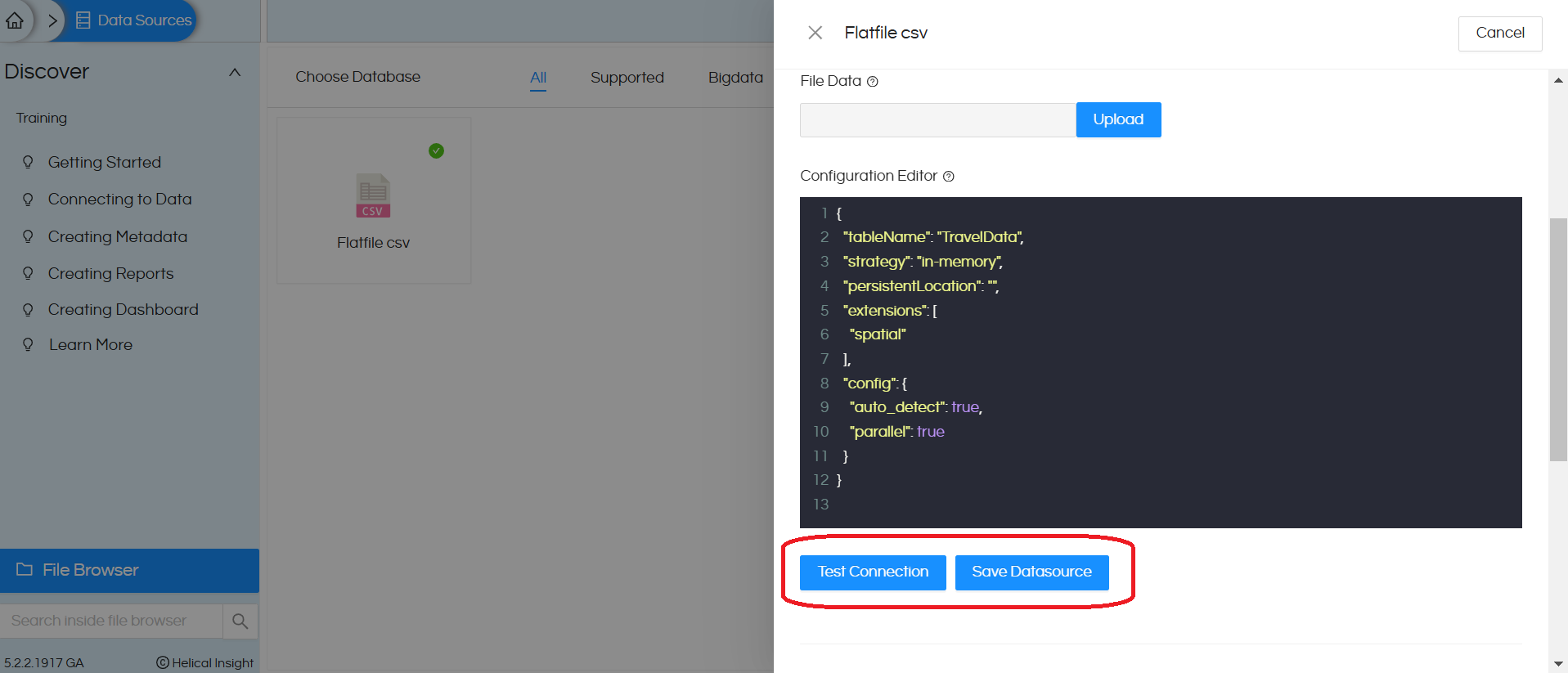
8. We have uploaded the “TravelData.csv” file using the ‘Upload’ option and provided the required configuration in the Configuration Editor
{
"tableName": "TravelData",
"strategy": "in-memory",
"persistentLocation": "",
"extensions": [
"spatial"
],
"config": {
"auto_detect": true,
"parallel": true
}
}
9. Click on Test Connection, it gives The connection test is successful
(If there are no issues with configuration) click on Save Datasource
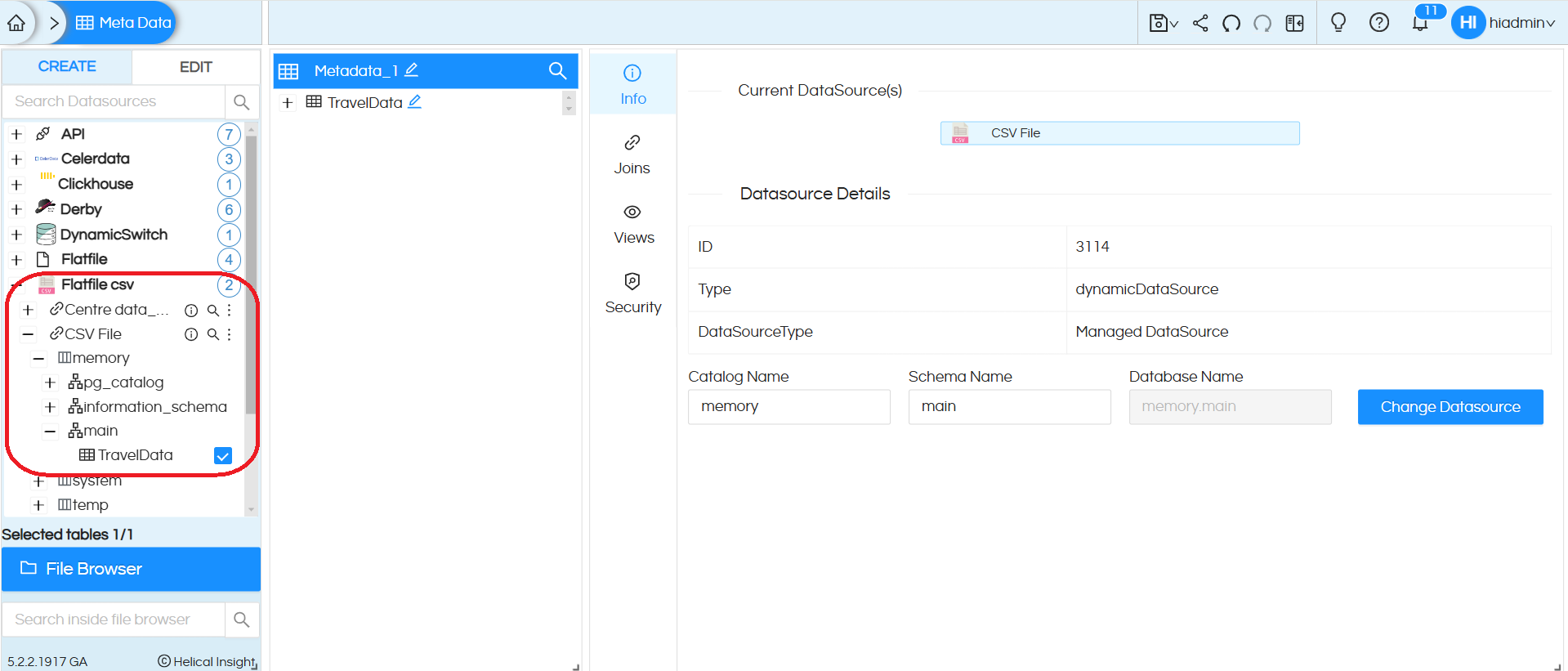
10. Go to the metadata page and expand the Flatfile csv data source. Then expand the CSV File connection. Expand ‘memory‘ and then ‘main’ and it will show the table name that we provided in the data source connection configuration. Drag the table into metadata
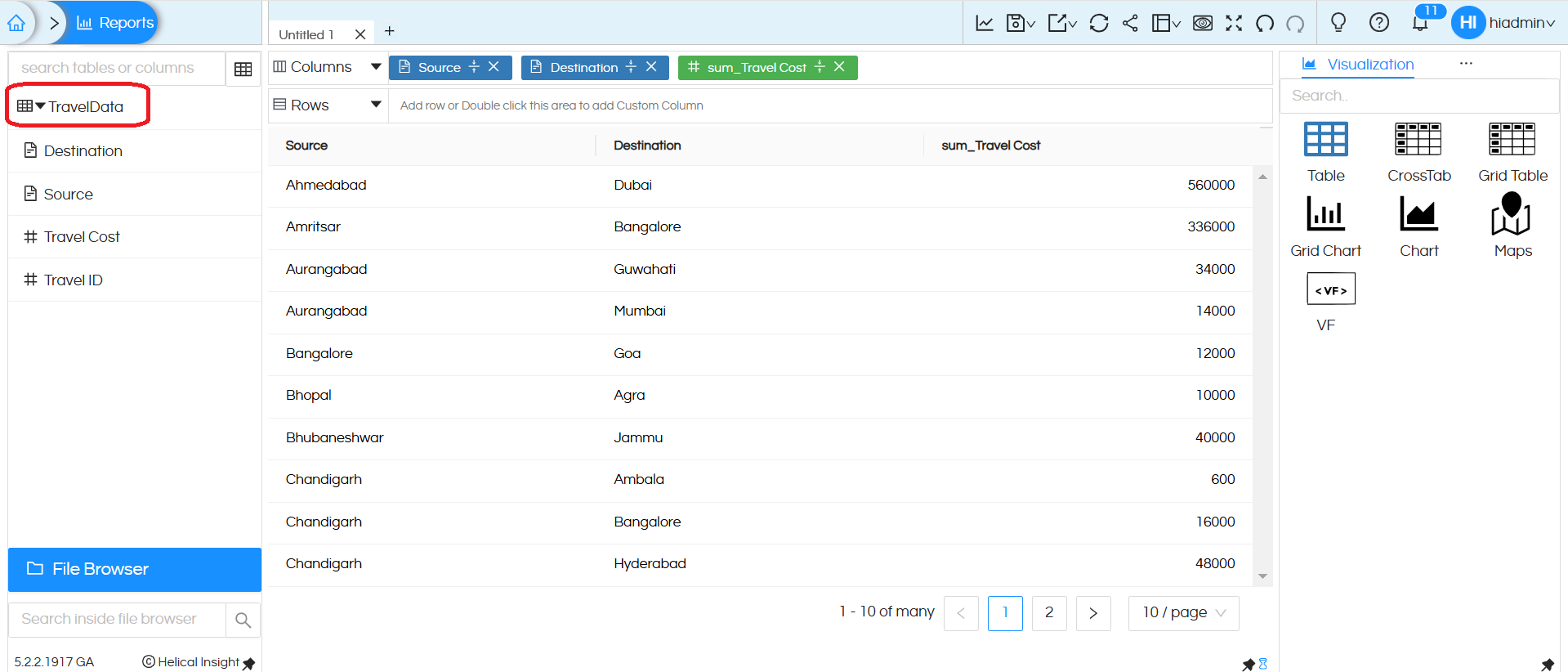
11. Create a report using the metadata and save it
NOTE: In the configuration, we can even add more and more configuration options also. Below can be referred.
| Name | Description | Type | Default |
|---|---|---|---|
| all_varchar | Option to skip type detection for CSV parsing and assume all columns to be of type VARCHAR. | BOOL | false |
| allow_quoted_nulls | Option to allow the conversion of quoted values to NULL values | BOOL | true |
| auto_detect | Enables auto detection of CSV parameters. | BOOL | true |
| auto_type_candidates | Allows specifying types for CSV column type detection. VARCHAR is always included as a fallback. | TYPE[] | default types |
| columns | Specifies the column names and types within the CSV file (e.g., {‘col1’: ‘INTEGER’, ‘col2’: ‘VARCHAR’}). Implies no auto detection. | STRUCT | (empty) |
| compression | The compression type for the file. Auto-detected by default (e.g., t.csv.gz -> gzip, t.csv -> none). | VARCHAR | auto |
| dateformat | Specifies the date format to use when parsing dates. See Date Format example below. | VARCHAR | (empty) |
| decimal_separator | The decimal separator of numbers. | VARCHAR | . |
| delim or sep | Specifies the character that separates columns within each row. | VARCHAR | , |
| escape | Specifies the string used to escape data character sequences matching the quote value. | VARCHAR | “ |
| filename | Whether an extra filename column should be included in the result. | BOOL | false |
| force_not_null | Do not match specified columns’ values against the NULL string. | VARCHAR[] | [] |
| header | Specifies that the file contains a header line with the names of each column. | BOOL | false |
| hive_partitioning | Whether or not to interpret the path as a Hive partitioned path. | BOOL | false |
| ignore_errors | Option to ignore any parsing errors encountered and ignore rows with errors. | BOOL | false |
| max_line_size | The maximum line size in bytes. | BIGINT | 2097152 |
| names | The column names as a list. | VARCHAR[] | (empty) |
| new_line | Set the new line character(s) in the file. Options are ‘\r’,’\n’, or ‘\r\n’. | VARCHAR | (empty) |
| normalize_names | Whether column names should be normalized by removing non-alphanumeric characters. | BOOL | false |
| null_padding | Pads remaining columns on the right with null values if a row lacks columns. | BOOL | false |
| nullstr | Specifies the string or list of strings that represent a NULL value. | VARCHAR or VARCHAR[] | (empty) |
| parallel | Whether or not the parallel CSV reader is used. | BOOL | true |
| quote | Specifies the quoting string to be used when a data value is quoted. | VARCHAR | “ |
| sample_size | The number of sample rows for auto detection of parameters. | BIGINT | 20480 |
| skip | The number of lines at the top of the file to skip. | BIGINT | 0 |
| timestampformat | Specifies the date format to use when parsing timestamps. | VARCHAR | (empty) |
| types or dtypes | The column types as either a list (by position) or a struct (by name). | VARCHAR[] or STRUCT | (empty) |
| union_by_name | Whether the columns of multiple schemas should be unified by name rather than by position. | BOOL | false |