In this blog we will cover how to connect Open Source BI product Helical Insight application with SQL Spark database. Click on “Data Sources” page.
- The list of Data sources is present as a collection of icons for each database.
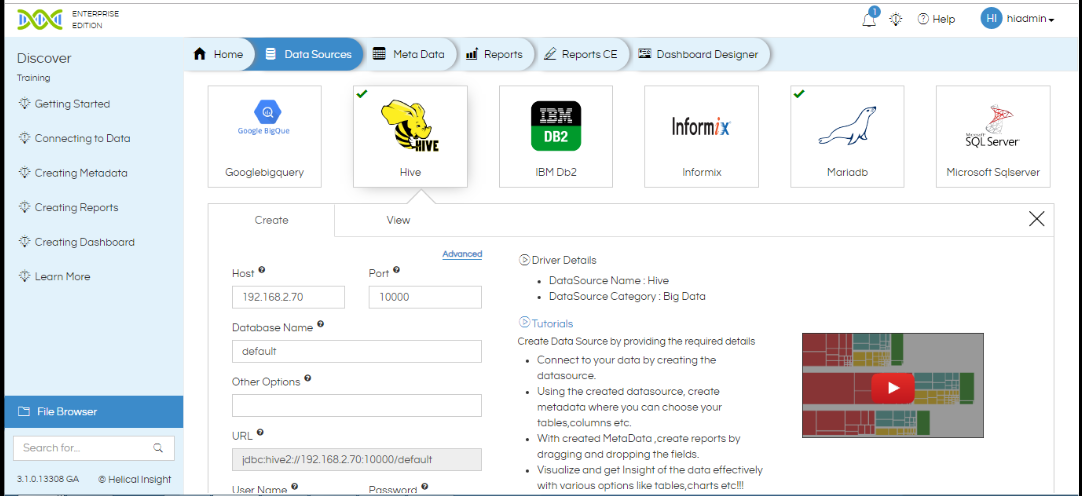
- Click on “Hive”.
- Now in the “Create” tab, enter the following details:
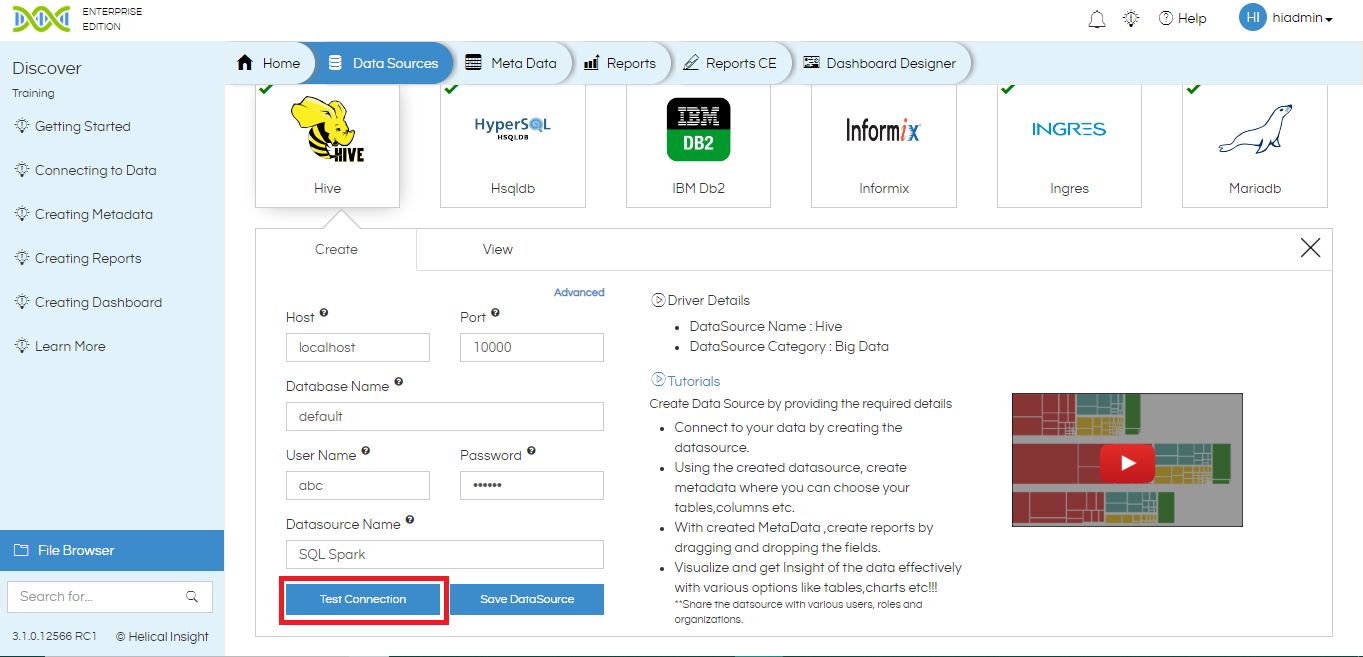
- Host: Enter the server details or IP where the database resides.
- Port: Enter the port number to connect to your database server. For SQL Spark, default port is 10000
- Database Name: Enter the name of your database.
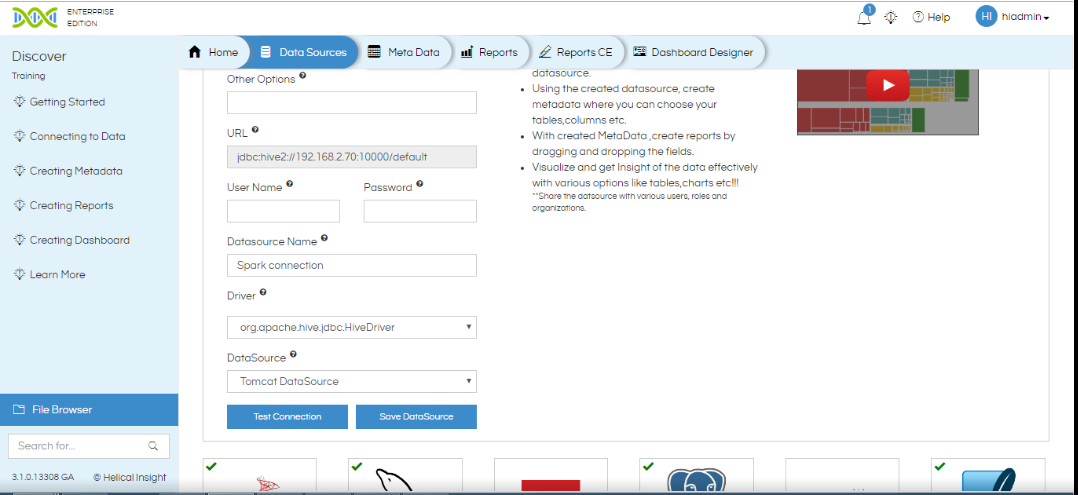
- User Name: Enter the username credential if required to access your database.
- Password: Enter the password credential if required to access your database.
- Data Source Name: Enter a name of your choice to the data source connection.
- Advanced: If you have any advanced settings required to access your database, click on “Advanced” link at the top right corner of the Create Tab. The additional fields are:
- Other Options: Enter the properties that are required additionally apart from the Host IP and Port to access the database. E.g.: ?sel=true.
- URL: This field shows the URL that is generated to create the JDBC connection. This can be used to verify if the properties are sufficient to access the database. In this case, the URL should look like below:
jdbc:hive2://[hostname]:[portnumber]/default
- Driver: This field shows the driver that is being used to establish the connection. It can be changed if required.
- Datasource: This is the name of the datasource provider. By default it is Tomcat. It can be changed, if required.
- Once all the details have been filled, click on Test Connection.
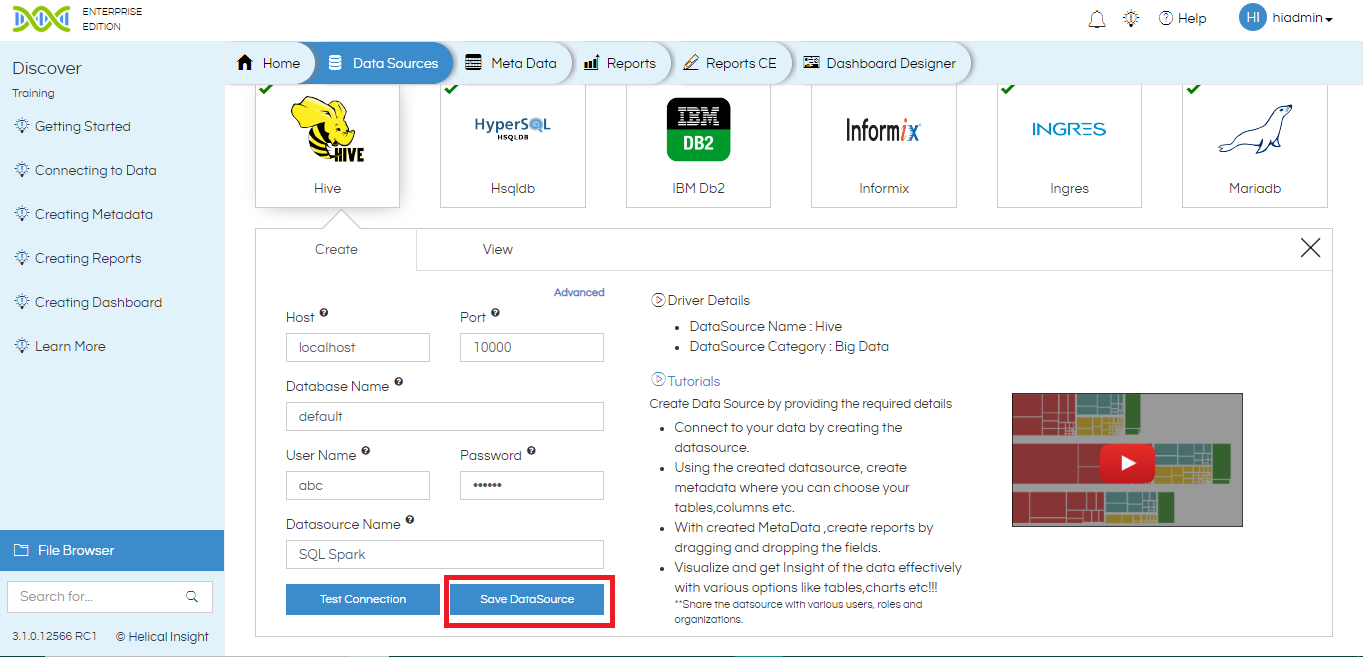
If the test is successful, click on Save Data Source to save the data source connection.
Once the connection is successful you can then click on “View” and view the connection which has been made. Now you can create metadata from this saved connection which can then in turn be used for reporting purposes.
For further assistance kindly contact us on support@helicalinsight.com