Introduction: Helical Insight metadata connects with a database which is predefined. Now there might be certain cases in which we would like the metadata to connect to different datasources based on certain condition.
For example : In healthcare industry the data of the hospital can not go outside the hospital premises. In that case, based on which hospital user has logged in, the metadata should connect to a different physical database.
Note: This solution will work if the DBName, table name, column name and schema is same,even though the physical server, DB credentials etc could be different.
NOTE: This solution will only work with Helical Insight Enterprise Edition.
Below is the flow diagram which explains the overall flow of Dynamic Database Switching.
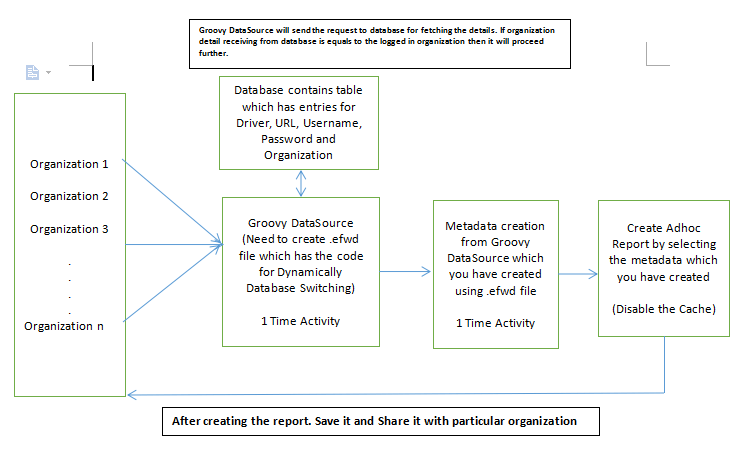
Steps to be followed to connect with different datasources.
Step 1:Using any editor like notepad++ create a file with an extension .efwd containing datasource connection details and conditions for checking which organization/user/role is logged in and accordingly connecting to a different database. Now create folder in the Helical Insight repository with any name and Save this .efwd file in the created folder.
Location for Helical Insight repository is: ..\Helical Insight\hi\hi-repository
Note: In your case location can be different based on the Helical Insight installation directory.
Sample code for EFWD DataSource is shown below:
<EFWD>
<DataSources>
<Connection id="12" type="sql.jdbc.groovy">
<Driver>com.mysql.jdbc.Driver</Driver>
<Url>jdbc:mysql://localhost:3306/SampleTravelData</Url>
<User>root</User>
<Pass>root</Pass>
<Condition>
<![CDATA[
import groovy.sql.Sql;
import net.sf.json.JSONObject;
import com.helicalinsight.adhoc.metadata.GroovyUsersSession;
public JSONObject evalCondition() {
JSONObject responseJson = new JSONObject();
String orgName = GroovyUsersSession.getValue('${org}.name');
orgName = orgName.replaceAll("'","");
sql=Sql.newInstance('jdbc:mysql://localhost:3306/details', 'hiuser', 'hiuser', 'com.mysql.jdbc.Driver');
sql.eachRow( 'select * from details' ) {
if(orgName.equalsIgnoreCase(it.organization)){
responseJson.put("driver",it.driver);
responseJson.put("url",it.url);
responseJson.put("user",it.user);
responseJson.put("password",it.password);
}
}
return responseJson;
}
]]>
</Condition>
</Connection>
</DataSources>
</EFWD>
Where:
DataSources
It is a collection of connection(s) that are to be used by the adhoc module.
Connections
It defines a connection, and the parameters of the connection that are provided via its child-nodes. It must also have an unique id attribute (used for its identification) and a type attribute (depends on settings). Here type must be sql.jdbc.groovy.
Driver
Driver details of the Database you want to connect. Here we are connectiong the MySql database so Driver is provided as com.mysql.jdbc.Driver
URL
Url of the database you want to connect. It contains the host address with database name.
Example:jdbc:mysql://localhost:3307/SampleTravelData
Username:Username of the database.
Password:Password of the database.
Condition:Here we define the condition for checking which organization/user is logged in and based on the condition we will pass the Driver details, Url, Username, Password. The code which is written in the Condition Tag is in the Groovy language.
In sql we write the sql query to fetch the data from database where datasource details are defined. From there we will retrieve the datasource details which can be used for maintain the datasource connection depending on the organization. Using sql.eachRow we loop over rows fetched from the database.
Note:Organization Name in the database and organization created with Helical Insight application must be same.
Sample Database is like below:

Example:
<![CDATA[
import groovy.sql.Sql;
import net.sf.json.JSONObject;
import com.helicalinsight.adhoc.metadata.GroovyUsersSession;
public JSONObject evalCondition() {
JSONObject responseJson = new JSONObject();
String orgName = GroovyUsersSession.getValue('${org}.name');
orgName = orgName.replaceAll("'","");
sql=Sql.newInstance('jdbc:mysql://localhost:3306/details', 'hiuser', 'hiuser', 'com.mysql.jdbc.Driver');
sql.eachRow( 'select * from details' ) {
if(orgName.equalsIgnoreCase(it.organization)){
responseJson.put("driver",it.driver);
responseJson.put("url",it.url);
responseJson.put("user",it.user);
responseJson.put("password",it.password);
}
}
return responseJson;
}
]]>
In this case we are checking which organization is logged in and depending on the organization we are changing the datasource details. Similarly it can be used to check for role or user by using ${role}.name and ${user}.name respectively. Database column details can be fetch by ‘$it.column_name’
Step 2:Go datasources tab.
Step 3:Click on Advanced
Step 4:Select the Datasource type as the Groovy Plain Jdbc DataSource.

Step 5:Select created groovydatasource in the View tab. Also Test the connection. Click on “Create Metadata”.
Step 6:You will be navigated to metadata page. You can hover over the Info icon and can see the kind of datasource type (groovy in our case).

Step 7:Create metadata from this connection. By default in current database field the database name is visible we have to remove that current database name and then save the metadata. Then that metadata can be used for reports and dashboards creation.
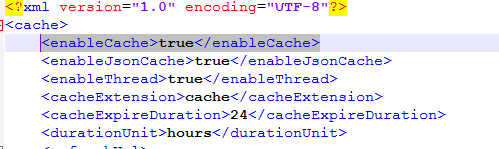
Step 8:Disable the cache in Helical Insight
1). To disable the cache go the Helical Insight Admin folder and open the cache.xml file for editing it and set <enableCache> to false.
Location: ..hi\hi-repository\System\Admin\cache.xml
Note:In your case location can be different based on the Helical Insight installation directory.
2). Login to Helical Insight Application using the super admin credentials and click on the cache button of Reload Setting. This will reload the cache setting of Helical Insight.

Now login to the different organization to access the report to see the data associated with that organization.
